An AI Fable: Why Models Should Matter to Leaders in Wine

👋 Hi, I'm Stephen. I help wine professionals learn about AI through curated news, topic breakdowns, and how-to guides.
P.S. the newsletter is back after a while. We were building New Vintage, the secure platform for wineries to connect their DTC data to AI tools.
LAST TUESDAY, Anthropic launched a new AI model called "Fable 5", the first model of a highly anticipated next generation series.
On Friday, the US Government issued a directive requiring removal of access for any foreign national. The only practical way to comply was to remove access for everyone.
Today, we'll talk a bit about the biggest AI release of the year (so far), why I think models are important for leaders in the wine industry to understand, and how this impacts performance within the AI tools you use.
Note: This is an evolving story, and this post may not include the most up to date information. I encourage you to seek out updates and different perspectives.
What happened
Anthropic released Fable 5 and Mythos 5 (official blog post), two versions of the same class of model, with Mythos having fewer security restraints, only available for specific teams.
This release is coming on the back of their April announcement of Project Glasswing, a public/private research partnership to work with the top cybersecurity teams in the world to ensure that AI models are used for (security) good.
Here's a snippet from the Glasswing announcement:
Over the past few weeks, we have used Claude Mythos Preview to identify thousands of zero-day vulnerabilities (that is, flaws that were previously unknown to the software’s developers), many of them critical, in every major operating system and every major web browser, along with a range of other important pieces of software.
The Mythos Preview model was not only deemed too powerful to safely release, but that a broader, coordinated effort was required to patch existing systems and shepherd appropriate use.
Just two months later, Fable 5 is the first "Mythos-class" model to be deemed safe enough to release commercially. Safeguards were added to the model to mitigate the possibility of it performing certain tasks or otherwise engaging with risky surface areas of topics.
The US Government, who had early red-team (security testing) access before the release, believed it had found a "jailbreak" last week, or a way to circumvent these security safeguards, leading to the directive.
Anthropic's most capable model ever released to the public was unreleased because of an unconfirmed jailbreak. Now they're scrambling to get the ban lifted.
Why this matters (tin-foil hat edition)
For starters, we now have the federal government sufficiently concerned that a model is too dangerous for a foreign national to access, that they took a very public measure for an unconfirmed vulnerability. It's unclear whether this finding was raised during their early access window or after the public release. Either way, it feels like a public fumble.
I also wonder if this is part of Anthropic's marketing? Super scary, too powerful, "we've created a monster", conveniently hyped before their IPO. I haven't quantified this, but I suspect engagement and earned media is good. It might very well backfire.
Regardless, given that today is the worst the models will be, meaningful advancements are happening multiple times a year, and researchers are pursuing model self-improvement, what is the right approach to a public-private collaboration? How do you "regulate" something moving this fast?
I'm not sure, but everything at the core of this story is happening at one layer: the model.

But what is a model?
I recognize that many of you may not follow AI model advancements regularly, or at all, so let's do light refresher.
Models are the brains of an AI system. Think of them as portable intelligence that can be called in different ways, but cannot take action on its own. I think of the floating heads from Futurama, where different models vary in knowledge, personality, and capability. Each model would be a different floating head.
A select few companies/groups in the world develop AI models that the rest of us use either commercially (baked into products we use and/or use via API directly) or "open-source" (usually free, but you use/maintain it on your own).
OpenAI, Anthropic, Google, etc. fall primarily in the commercial bucket, where we rent their "closed" models (i.e. we can't see how they work, exactly).
Models are typically measured against each other on various task benchmarks, evaluating the model's performance on a given set of tasks, using a neutral harness (this is a separate post), then most often ranked in a blind human-preference system. These are, of course, imperfect and evolving.
Every few months, new models are released that improve on the various internal and external benchmarks.
While it's possible to train your own models, it's currently quite expensive to do and requires a specific set of skills.
Assume that almost all AI products you encounter use one or more different models. Developers of these products are not training their own models, but they are controlling when, where, and how they are used.
The leap to AI agents is the transition to providing the "body" through which models can operate with greater freedom. A topic for another issue.
Why this matters to you
I believe, quite strongly, that leaders in the wine industry need to know how this stuff works, in order to right-size team efforts and expectations.
This is about knowing what's possible, so that you can identify your high leverage opportunities sooner. This is also about broadening the pool of people in-the-know, so we can all get this right. So here goes...
Fable 5 is supposed to be a particular step forward in long-running, complex knowledge work tasks. Consider this snippet from their announcement:
...it can work for days at a time: planning across stages, delegating to sub-agents, and checking its own work.
To put that in perspective...
- in June 2024, the big AI milestone was OpenAI launching the 4o model that could perform live translation (the same launch may have ripped off Scarlett Johansson's voice)
- in June 2025, most major models were outscoring human experts with, or pursuing, PhDs on the GPQA Diamond benchmark for graduate-level science reasoning
- in June 2026, Fable 5 apparently beat Pokémon FireRed using just vision. An innocent example that represents hours of "see" -> "interpret"-> "do" loops
Model improvements matter because they are advancements in core capability; the difference of one more task being completed correctly, one fewer correction etc.
Here are some cascading effects that may be non-obvious if you don't follow this stuff regularly.
Your chats get better
This means that when you or your team are interacting with your AI of choice, you can use different models, trading off cost and capability as needed.
Let's look at a simple example of the same request about DTC sales data, using Claude Cowork, with the New Vintage Claude Connector (small plug - available to our pro customers), changing only the model.
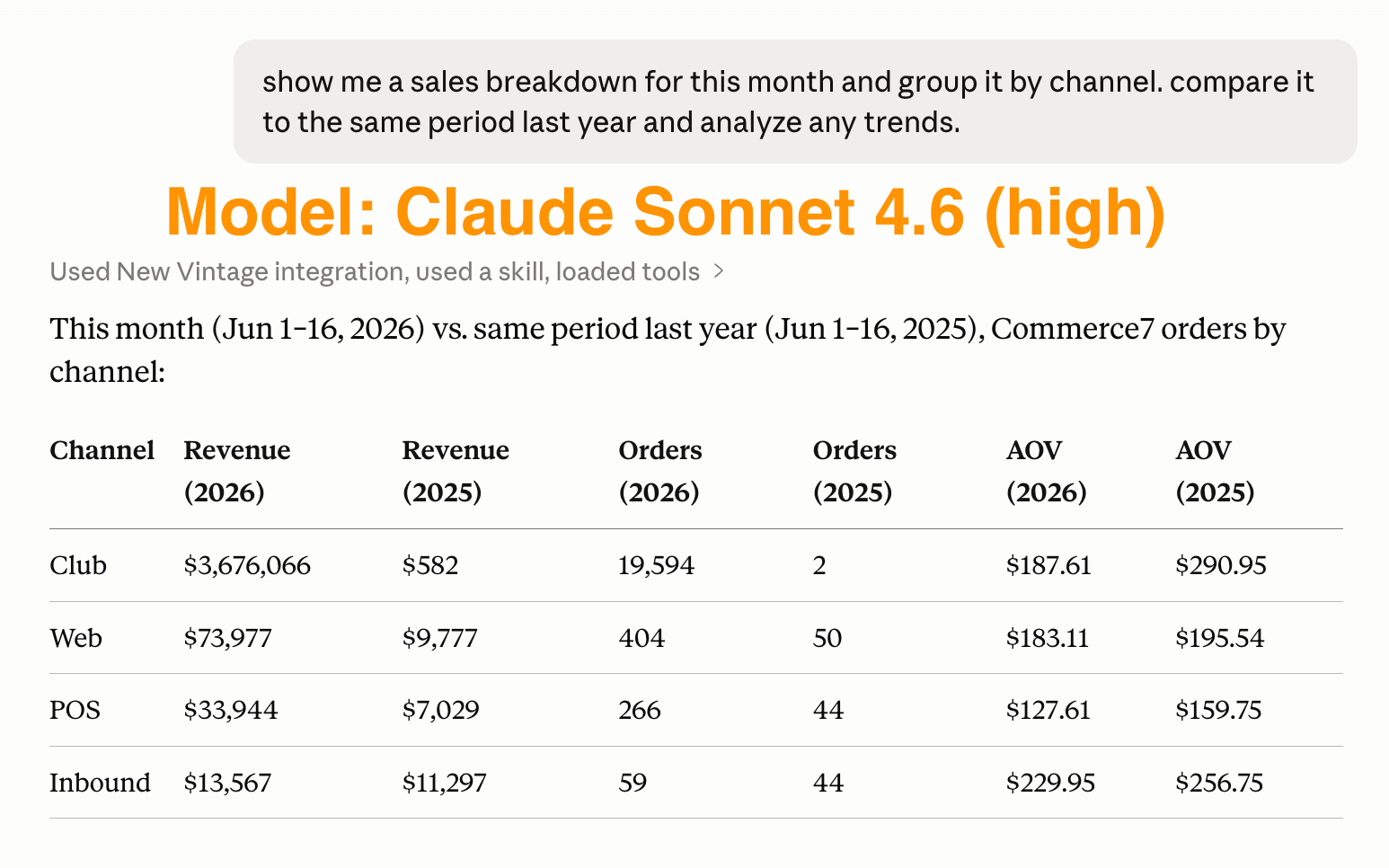

The instructions are the same, the access to the data is the same, and one produces a valid answer, while the other doesn't.
If your team is running on assumptions based on what AI could do last year, or you haven't tried multiple models, I would encourage you to experiment openly.
There are more than a few variables that contribute to "performance" here, so let me know if you want a deeper dive.
Cyber security looks different
This is at the core of the Mythos announcement and, hype or not, the curve we're on with AI development is going in one direction.
So, if we reason about what we've seen thus far: models and their accompanying harnesses are being optimized for software engineering, knowledge work, research, etc., then it's reasonable to assume that cyber attackers will be armed with these capabilities. As that happens, the sophistication, volume, and coordination of attacks will be unrecognizable to us.
The other side is equally true, where our "defense" systems will need to be appropriately dynamic, and the software teams we choose face a real challenge in reimagining what security of their systems looks like.
This is not my area of expertise, and there is no call to action, but it felt negligent not to point this out. We have to lean in.
What's possible expands
In the early days of ChatGPT, you could ask a basic math problem or current events question and it might have "hallucinated", or returned incorrect information. This is because it was trying to answer based on its "knowledge", without the ability to use any tools to actually perform calculations or seek information from the internet.
While chat is still the most common product medium for interacting with AI models (ChatGPT, Claude, Gemini, Copilot, etc.), it's no longer limited to text, or even Q&A.
As models improve, new capabilities are formed, and use cases are unlocked.
Here are some examples:
Improvements in ____ (have made) -> ____ possible
- instruction following -> workflows/skills: the ability to follow an SOP or the principles of a guide are dramatically better, so now we can codify them into reusable skills that AI can "use" at the right moment. Got a funny way you set up your club? Build a skill.
- context windows + reasoning -> tool use/connectors: longer context windows (basically attention span), with the ability to "think" before acting, has made it possible for AI to decide which external system(s) to use, and what to do within them, then iterate based on the data received. This is the transition from Q&A to multi-step task completion.
- multi-modal processing -> image/pdf understanding: it's surprisingly complex for a computer to "see", and understand, an image or pdf. As models have gotten better at this, suddenly you can "show" it more, and have it understand visual context. Aka it can help you interpret Ikea assembly instructions or help your sales rep understand your tech sheet.
Capabilities compound and can then be incorporated into existing products, like chat interfaces, in non-obvious ways. The simplest heuristic: more stuff just works.
Complexity gets cheaper
I know some of the above can be a bit abstract, but we're here for the journey, right? Let's go further.
Imagine you want to make all your company pdfs searchable. IT has left the chat.
You could upload all those pdfs to a chat and fire away, right? Well, you could only add so many. Fine, make a project in your team Claude, add a ton of files. But, that doesn't stay updated. Ok, but what if you use a connector, for Microsoft Sharepoint, that then allows Claude to retrieve files whenever it wants?
Now we're getting somewhere, but along the way, you notice that the company policy doc with the do's and don'ts table was incorrectly referenced. What gives?
It turns out that different models are, concretely, better at "parsing" pdfs (making it machine-readable) than others. Not only that, the cost to do so varies, and the product/process/harness used matters as well.
Consider this analysis from ParseBench and remember our friend Claude Fable 5:
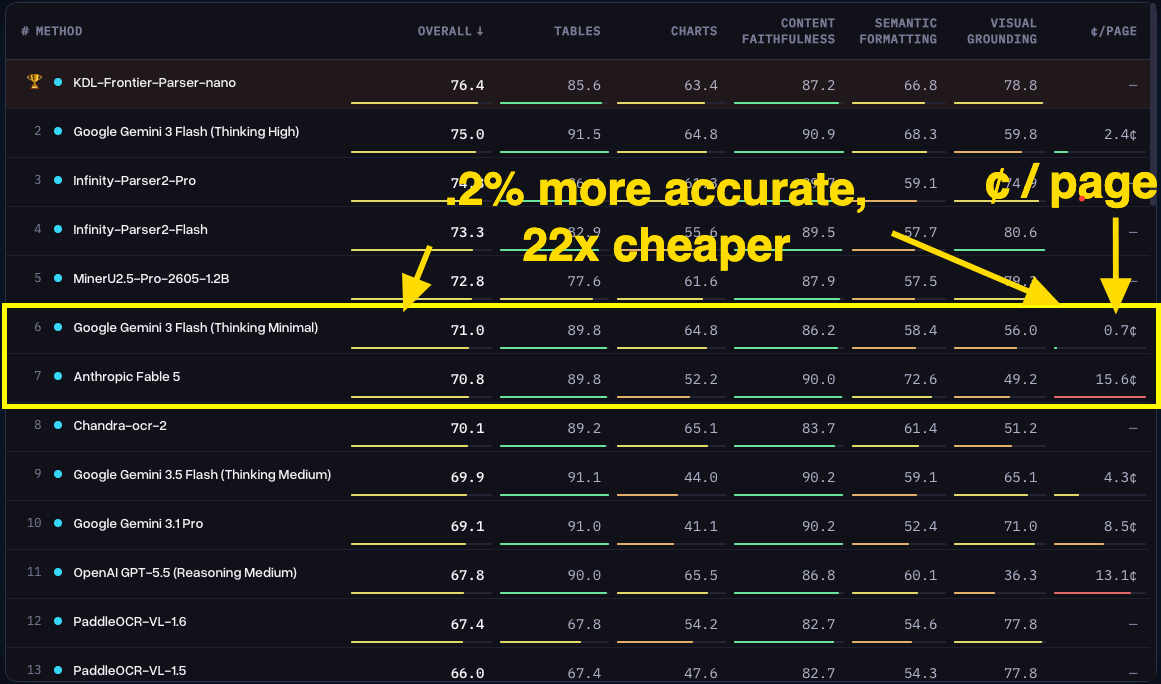
Gemini 3 Flash, not even Google's most "advanced" model, had essentially the same accuracy in parsing pdfs as the new Fable 5 model...while being 22x cheaper.
Remember Haiku 4.5 from before? It might get about half of the contents properly parsed, while being about twice as expensive as Gemini 3 Flash.
Yet, if you try to use Gemini 3 Flash to interpret the contents of many of these pdfs, in the context of your team, in the current market, while considering your strategy this year, you might have a pretty bad time. Fable 5, or other high-powered reasoning models, will likely give you much more useful output.
All this to say, there are real, monetary advantages to learning beyond the basics of how to use AI to write emails (though this is useful!). In fact, how much better would that email be if it was informed by the correct customer history, with the most recent company policy, and sent as a text because the customer prefers it?
The more you learn and experiment, the "cheaper" complexity will become.
Organizational design evolves
If long-running tasks, across many systems, can be autonomously completed, how might that influence how you coordinate resources for your company?
I know, it's heady. This is not the "fire everyone, AI will do everything" section. In fact, I would argue that your org's capacity to do so is lower the lesser your AI talent density is.
This is the introduction of a question: how much of how we work still makes sense?
I'm not doing great at this, and our company is likely much smaller than most of yours, but we're in the mud trying to figure it out.
So what can you do next?
If you/your team are just getting started with AI, pick some easy computer tasks and try them using ChatGPT, Claude, or Gemini. Use different models and watch some 101 videos on YouTube. Use it for one hour a day, try different models, and experiment with how you're asking for output.
If you're plateauing in chat, consider any of: paying for the paid version, adding custom instructions to projects, using connectors, using/making skills, using plugins, scheduling tasks, seeing if there's a product that solves your problem, using AI to build that product, moving to Claude CoWork/OpenAI Codex.
If you're solid with Claude CoWork and the above, identify your specific bottleneck(s) and consider: should this be code? Did you scope this properly? Is there context/data missing? Consider whether you need your own agent with evals.
If you want to work with your DTC data + AI, check out our platform, New Vintage.
If none of these apply, let me know in the comments what you want me to cover or email me at cheers@newvintagelabs.com
Follow along for more about AI for wine professionals. I'll write more if you want it.
If you found this useful, consider sharing with a colleague as I'd like to reach as many people in our industry who might find value.
Cheers,
Stephen

Comments ()